
It is possible to use neural networks to learn about data that contains neither target outputs nor class labels. There are many tricks for getting error signals in such non-supervised settings; here we'll briefly discuss a few of the most common approaches: autoassociation, time series prediction, and reinforcement learning.
A linear autoassociator trained with sum-squared error in effect performs principal component analysis (PCA), a well-known statistical technique. PCA extracts the subspace (directions) of highest variance from the data. As was the case with regression, the linear neural network offers no direct advantage over known statistical methods, but it does suggest an interesting nonlinear generalization:
This nonlinear autoassociator includes a hidden layer in both the encoder and the decoder part of the network. Together with the linear bottleneck layer, this gives a network with at least 3 hidden layers. Such a deep network should be preconditioned if it is to learn successfully.
A more powerful (but also more complicated) way to model a time series is to use recurrent neural networks.
Q-learning associates an expected utility (the Q-value) with each action possible in a particular state. If at time t we are in state s(t) and decide to perform action a(t), the corresponding Q-value is updated as follows:
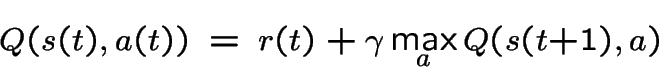
where r(t) is the instantaneous reward resulting from our action, s(t+1) is the state that it led to, a are all possible actions in that state, and gamma <= 1 is a discount factor that leads us to prefer instantaneous over delayed rewards.
A common way to implement Q-learning for small problems is to maintain a table of Q-values for all possible state/action pairs. For large problems, however, it is often impossible to keep such a large table in memory, let alone learn its entries in reasonable time. In such cases a neural network can provide a compact approximation of the Q-value function. Such a network takes the state s(t) as its input, and has an output ya for each possible action. To learn the Q-value Q(s(t), a(t)), it uses the right-hand side of the above Q-iteration as a target:

Note that since we require the network's outputs at time t+1 in order to calculate its error signal at time t, we must keep a one-step memory of all input and hidden node activity, as well as the most recent action. The error signal is applied only to the output corresponding to that action; all other output nodes receive no error (they are "don't cares").
TD-learning is a variation that assigns utility values to states
alone rather than state/action pairs. This means that search must be
used to determine the value of the best successor state.
TD(![]() )
replaces the one-step memory with an exponential average of the network's
gradient; this is similar to momentum, and can help speed the transport
of delayed reward signals across large temporal distances.
)
replaces the one-step memory with an exponential average of the network's
gradient; this is similar to momentum, and can help speed the transport
of delayed reward signals across large temporal distances.
One of the most successful applications of neural networks is TD-Gammon,
a network that used TD(![]() ) to learn the game of backgammon
from scratch, by playing only against itself. TD-Gammon is now the world's
strongest backgammon program, and plays at the level of human grandmasters.
) to learn the game of backgammon
from scratch, by playing only against itself. TD-Gammon is now the world's
strongest backgammon program, and plays at the level of human grandmasters.